Breaking Barriers to Data Access
At MrScraper, we don’t just build scrapers—we build transparency. As a self-funded company, we believe in making data accessible to everyone while embracing the Open Startup philosophy. From growth metrics to salaries and team diversity, we share it all. Because data should be open, and so should we.

What is
MrScraper?
MrScraper is an web scraping API and proxy infrastructure platform designed to extract data from websites reliably and at scale.
It combines residential and datacenter proxies, browser automation, and anti-blocking technology to ensure high success rates for data extraction tasks — whether you're scraping one page or ten million.
Built with developers in mind, MrScraper abstracts the complexity of web scraping into a simple, powerful API that handles everything from IP rotation to JavaScript rendering automatically.
// MrScraper Web Scraping API
const scraper = await createAiScraper({
url: 'https://example.com/products',
message: 'Extract all product names and prices',
agent: 'listing',
});
// ✓ 200 OK — data extracted
// ✓ proxy rotated automatically
// ✓ CAPTCHA bypassed
What MrScraper
Provides
MrScraper delivers a complete, production-ready scraping stack—no patchwork tools or custom infrastructure required.
Common
Use Cases
Built for Scale
and Reliability
Unlike traditional scraping tools that break on page structure changes or get blocked immediately, MrScraper is engineered for high-volume data extraction with fault tolerance at its core.
Automatic proxy rotation, adaptive anti-blocking, and cloud-scale infrastructure means you spend time using data — not debugging scrapers.
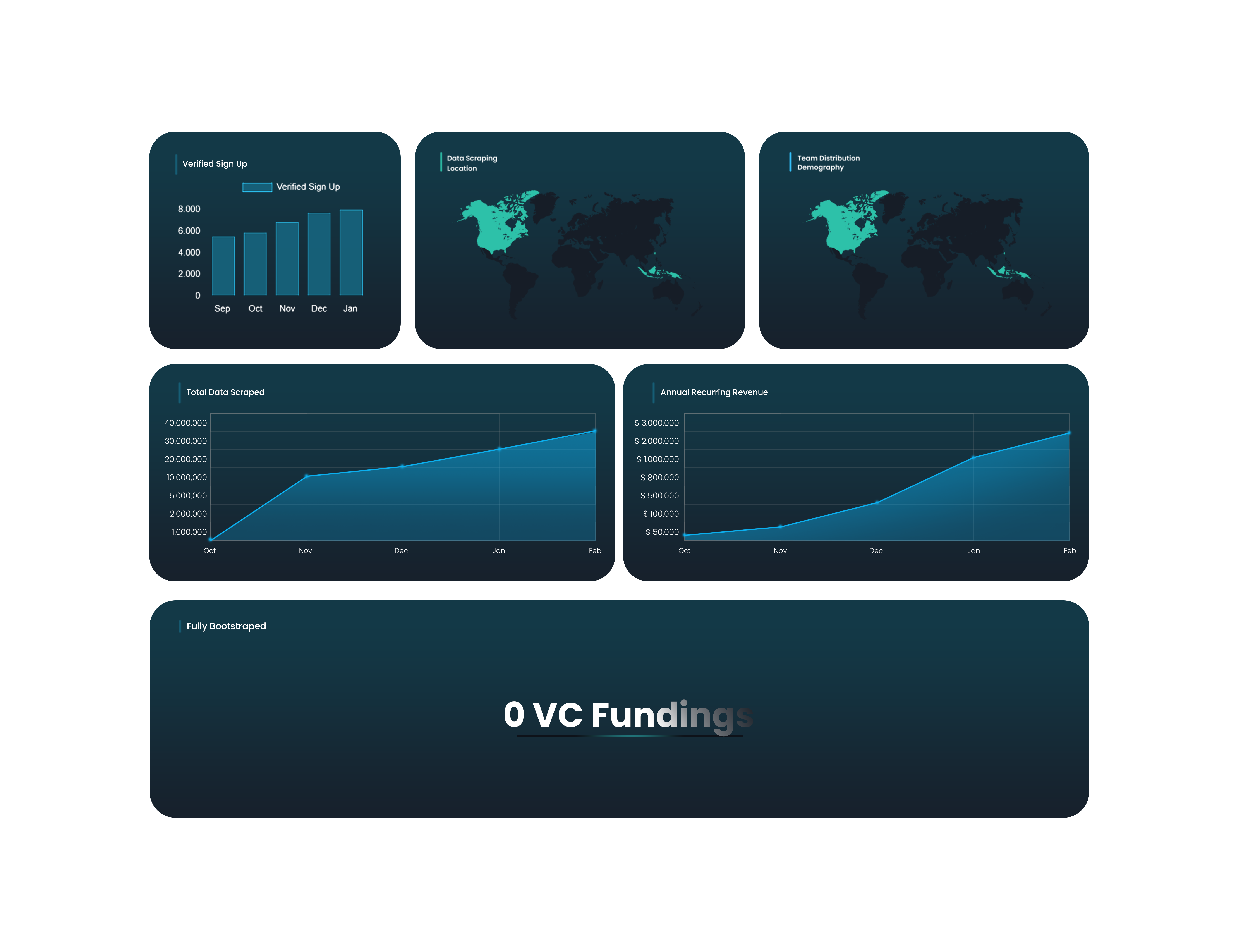
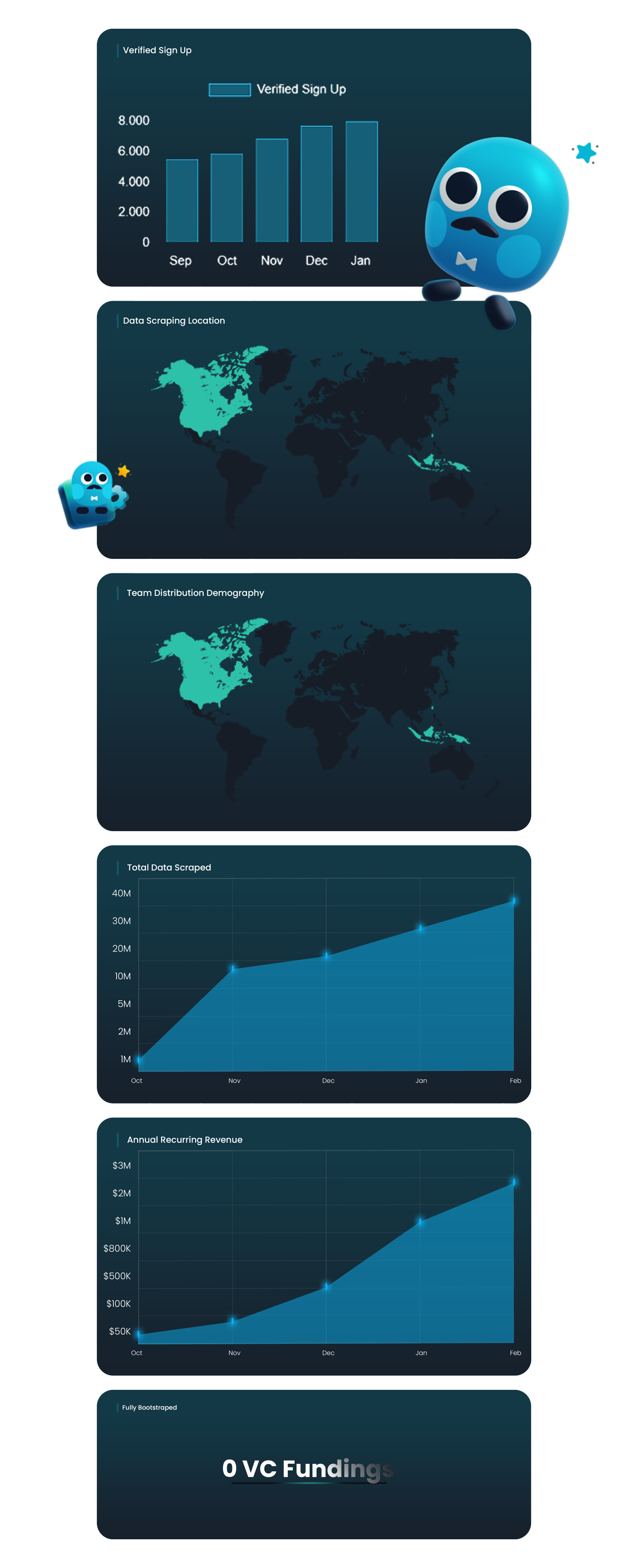
Open Metrics: Inside Mrscraper’s Growth
From global operations to verified signups—see how we’re scaling transparency.